 admin
admin数据增强的目的是在不足的数据场景中生成额外的合成训练数据。数据增强范围从基于规则等简单的方法到可学习的基于生成的方法,上述所有方法基本上保证了增强数据[29]的有效性。也就是说,DA(data augmentation)方法需要确保增强的数据对任务有效,即被认为是原始数据[29]相同分布的一部分。例如,机器翻译中相似的语义,文本分类中相同的标签。
文中将文本增强的方法划分为:
基于对句子的适当和受约束的变化,生成与原始数据语义差异有限的增强数据。增强的数据传递的信息与原始形式非常相似;
在保证有效性的前提下增加了离散或连续的噪声。该方法的目的是为了提高模型的鲁棒性。
学习原始数据的分布,并从中采样出新的样本。这种方法可以输出更多样化的数据,满足下游任务更多的需求。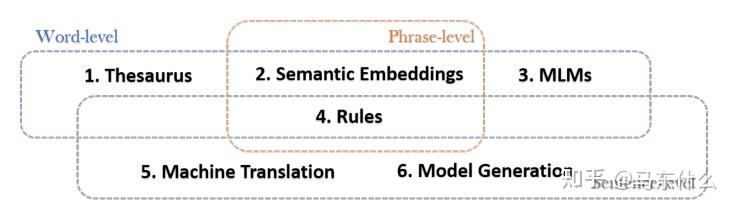
整体上从词,词组和句子的层面进行paraphrasing-based的增强。方法如下: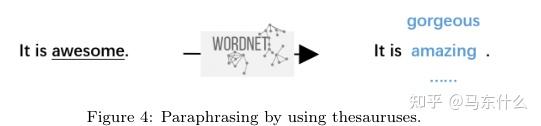
例如wordnet或者中文同义,近义词词典等,来做同义词或近义词替换,策略层面介绍了EDA,https://github.com/425776024/nlpcda#7%E7%AD%89%E4%BB%B7%E5%AD%97%E6%9B%BF%E6%8D%A2
常见的方法基本上通过nlpcda+自己定义的一些外部数据都可以比较方便的实现。同时也可以使用 一些词汇替代的候选词:副词、形容词、名词和动词。外部数据,github上有不少开源的可以好好找找.
这种方法的优点:
(1)易于使用;
缺点:
(1) 可替代的方案是有限的,同义词和近义词等是有限的;
(2)无法解决一词多义问题(基于外部数据的方法本质上是一种静态的方法)
(3)增强的粒度不好控制,需要大量的耐心和肉眼观察,比如说对于超短句,eda很容易破坏原始句子的语义;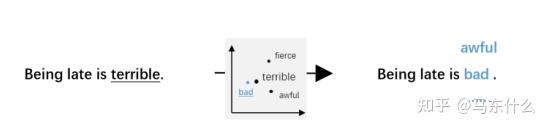
使用预训练的词向量,例如glove,fasttext,word2vec等来进行替换,通过gensim的most similar方法比较容易实现。
优点:
1 易于使用;
2. 更高的替换命中率和更大的替换范围(其实可以迭代引入外部数据的方法一起使用增加多样性)。
缺点
1.仍旧无法解决一词多义问题(毕竟词向量);
2. 过多的替换会影响句子的语义。(这种方法在业务中使用的时候效果一般,主要是因为预训练的词向量本身接受的语料对于词向量的作用影响极大,举个例子,假设某个预训练词向量是在唐诗宋词这样的语料上训练的,然后你拿来做微博评论的的文本增强,效果可想而知,如果预训练语料没有合适的选择,推荐自己使用自己的语料从头训练一个新的出来会比较好)https://paddlenlp.readthedocs.io/zh/latest/model_zoo/embeddings.html『NLP打卡营』实践课1:词向量应用演示 - 飞桨AI Studio - 人工智能学习与实训社区
这块儿paddlenlp相当全,省去了自己找语料下载,gensim加载的痛苦过程。
paddlenlp主要有两个地方我觉得比较好:
1.比较丰富的静态的词向量,使用起来也api设计也比较简单;
2.比较多的针对中文的预训练transformer-based model,比如比赛里面常见的nezha。
缺点就是,我懒得再学了,huggingface 的transformer够用了,也不想在花太多时间撸paddle了(找个时间看看有没有啥方法把paddlenlp的预训练model直接加载到huggingface transformers里来用)
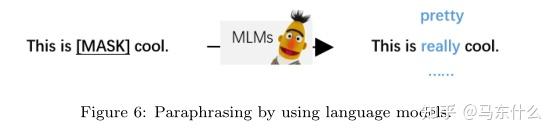
典型的就是MLM了,随机选个部分word出来mask掉然后用预训练模型预测取预测概率最高的。
优点:
1.结合了上下文的语义,替换更不容易产生乱七八糟的结果;
2.解决了一词多义的问题
缺点:
1.仍旧局限于word层面;
2.过多的替换会影响句子语义
(3. 计算速度比前两种慢太多了)
这部分也比较好实现(nlp和cv的高质量开源真的多的一笔,工程压力小不少呢)
一个是huggingface transformer的pipeline的设计以及paddlenlp的taskflow。
这块儿也是一样,预训练模型使用的语料不是很合适可以自己在自己的数据上finetune一下(retraining就不必了,计算成本太高了也没必要),考虑到paddlenlp的fintune用起来实在很繁琐(主要是一些报错或者是一些魔改还是要去撸paddlepaddle烦死了),下一步还是想想怎么把paddlenlp上的pretraining model 转成transformer下的pytorch_model.bin或tf_model.h5吧。。。。
使用一些启发式的规则对原始的句子进行变换,例如缩写,被动改主动,
优点:
1 易于使用。
2. 这种方法保留了原来的句子语义。
缺点::
1. 这种方法需要人工启发式;
2. 低覆盖和非常limit的变化。
1.回译:例如中文先翻译成英文再翻译回来
2.单向翻译:主要是一些跨语言任务上会用到..感觉一般都是用回译来做Googletrans: Free and Unlimited Google translate API for Python
通过某个方法(大家懂的)可以无限制的使用谷歌翻译来做回译,真的太特么方便简单又无脑了,回译之所以能够work主要原因还是使用到了谷歌翻译工具背后的强大的预训练模型,可以尽可能小的程度改变原来句子的语义.真的是简单又好用效果还好,屌的一批.通过翻译工具的py接口,非常的迅速完成增强.
优点:
1 易于使用
2. 强大的适用性。
3.此方法确保语法正确,语义不变。
缺陷:
1 机器翻译模型固定,可控性差,多样性有限
(多样性问题不难解决...第一通过多个翻译工具的py接口,第二是通过使用多种语言的翻译,第三是翻译成英文之后可以把前面提到的方法结合进来)
这块儿的本地化可以考虑使用t5之类的多语言版本的model,更加方便一点,不过增强起来速度非常慢就是了。。
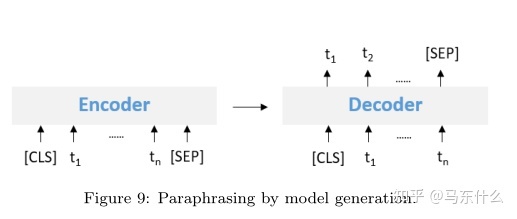
使用seq2seq来生成语义接近的句子,从形式上类似于做回译,不过本质上不一样,回译的建模是一个机器翻译过程,虽然也是seq2seq式的,但是其主要目标在于机翻不在于生成,而这里的生成方法主要关注于文本的生成,机翻和文本生成的关注点不一样,就好比seq2seq可以用来做机翻也可以做时序预测一样.
chatgpt当道的今天,生成式模型应该更加牛逼了吧,简单的做法就是直接使用chatgpt或者gpt来做文本生成,生成和原句子语义类似的新句子、
优点:
1 强大的多样性;
2. 强大的应用程序(???没明白什么意思 strong application)。
缺点:
1 需要训练数据
2. 高训练难度
(3.需要较为熟悉文本生成)
paraphase-based的方法的重点是使扩充样本的语义尽可能与原始数据相似。
而基于噪声的方法主要的做法是增加不太严重影响语义的微弱噪声,使其与原始数据适当偏离。这也是我觉得文本增强和对抗样本交叉的部分,很多地方的思路非常相似.
随机交换word的位置,随机删除,随机插入,随机替换(和paraphased-basd的方法不同,这里不使用和原始word相似的word进行替换,而是纯的随机替换).
这种噪声是黑产很喜欢做的,也是在反欺诈中会用到的一种样本增强方法,很有意思,举个例子,比如说陌陌和探探这类的社交类app经常会有仙人跳的骗子,通过私聊然后发 微信号码,qq号码的方式将平台的lsp用户导流到外部,从而便于避开平台本身的监控(比如转账之类的交易会进行限制或禁止),由于直接发送微信号很容易被正则这类简单的方法检测到,因此,假设我们的微信号是 1234567890,则黑产经常会做的事情是:
12微34x567890
12v34x56联78系90
v联123息45信6890
除此之外还有很多做法和上述noise based的方法很相似.
这种方法的优点仍旧是简单,并且主要目标在于通过提升模型的抗攻击能力或者说鲁棒性从而提高模型的泛化性能.
缺点在于粒度不好控制,尤其是短文本问题,swap或者deletion等处理很容易改变短文本的语义,例如"这部电影真他妈好看",删除了"好看"之后变成了这部电影真他妈,从positive完成了到negative的转变.所以会有一些tfidf,textrank之类的方法来帮助缓解这样的问题.
除了mixup需要使用其它的开源工具实现之外,其它方法基本上手撸都比较容易实现
(感觉这玩意儿起名叫特定任务的方法更好理解点)
基于抽样的方法是特定于任务的,并且需要任务信息,如标签和数据格式。这种方法不仅保证了有效性,而且增加了多样性。它们基于人工启发式和训练模型满足下游任务更多的需求,并可根据具体任务需求进行设计。因此,它们通常比前两大类更灵活和更难。Sampling是指从数据分布中采样出新的样本,不同于较通用的paraphrasing,采样更依赖任务,需要在保证数据可靠性的同时增加更多多样性,比前两个数据增强方法更难。from 李rumor:哈工大|15种NLP数据增强方法总结与对比
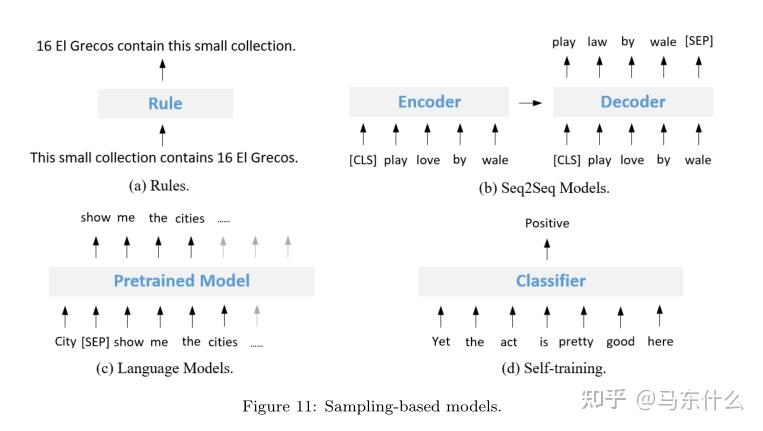
基于人工规则变换...牵强的说,这里的rule和paraphase-based中的rules的方法的不同在于是特定于某些任务的,更针对性的,不好推广到其它任务上的rules.优缺点和paraphse-based中的rules方法一样Some methods use non-pretrained models to generate augmented data. Such methods usually entail the idea ofback translation (BT)[83],12which is to train a target-to-source Seq2Seq model and use the model to generate source sentences from target sentences, i.e., constructing pseudo-parallel sentences [13].Such Seq2Seq model learns the internal mapping between the distributions of the target and the source, as shown in Figure 11(b). This is different from the model generation based paraphrasing method because the augmented data of the paraphrasing method shares similar semantics with original data.Sennrich et al. [84] train an English-to-Chinese NMT model using existing parallel corpus, and use the target English monolingual corpus to generate Chinese corpus through the above English-to-Chinese model. Kang et al. [28] train a Seq2Seq model for each label (entailment,contradiction, andneutral) and then generate new data using the Seq2Seq model given a sentence. Chen et al. [85] adopt the Tranformer architecture and think of the “rewrite utterance→request utterance” mapping as the machine translation process. Moreover,they enforce the optimization process of the Seq2Seq generation with a policygradient technique for controllable rewarding. Zhang et al. [13] use Transformer as the encoder and transfer the knowledge from Grammatical Error Correction to Formality Style Transfer. Raille et al. [29] create the Edit-transformer, a Transformer-based model works cross-domain. Yoo et al. [86] propose a novel VAE model to output the semantic slot sequence and the intent label given an utterance.
优缺点和上文提到的文本生成一样.
大型预训练生成模型生成样本,提到了著名的 LAMBDA,文中提到LAMBDA但是没有解释具体的过程,具体后面看看原论文再说吧.其它的,不想看了,压根看不完.
self training又出现了,这玩意儿真是啥领域都能来插一脚. 这里提到的self training方法,不过还是和表格一样两端式的,先预测样本,然后预测样本和原始样本一起拿来训练,话说我记得nn应该有一些paper是关于把这个过程包含到整个训练过程中的吧,有了解的大佬烦请告知一下.
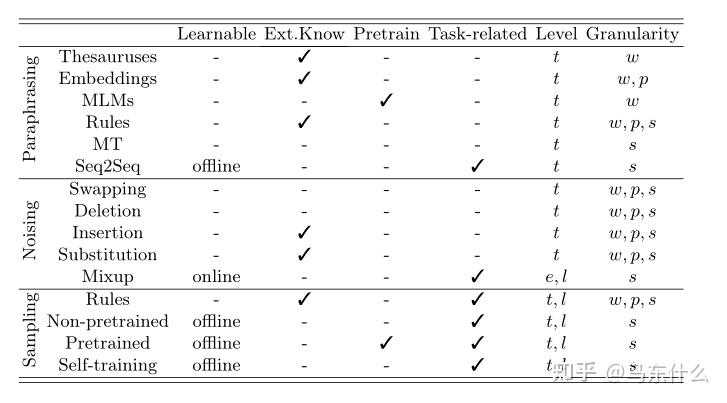
learnable表示是否可学习,learnable中online表示可以在线更新,offline则为只能离线更新;
EXT.Know表示是否需要外部的数据(知识,资料,etc)
pretrain即是否使用了预训练模型
task-related表示是否是任务相关的(简单来说这玩意儿是针对特定任务使用的放到别的场景上很容易不work或者压根也没法直接用到别的场景上)
level表示通过任务中的啥东西进行增强,t就是text,就是文本数据,e表示embedding,l表示label;
Granularity表示啥层面上增强,w表示词或者更严谨来说token,p表示短语或者更严谨来说subword,s表示sentence.
mixup和uda以及lambda,我后面有时间再看吧
1.多种方法可组合使用,效果可能更好;
2.无监督的方法可以先用,因为简单,快;
3.token,subword,sentence层面可以使用多种方法不一定只用一种,比如对token和sentence一起做mixup.
1.数据层面:
数据质量不高则可以
(1)将增强样本和原始样本合并为训练样本,
(2)模型先做个pretrain 再用;如果增强的样本太多,远远大于原始样本,则可以
(1)在训练模型之前对原始数据进行过采样
(2)使用增强数据对模型进行预训练,并在原始数据上进行微调。
2.超参数调整: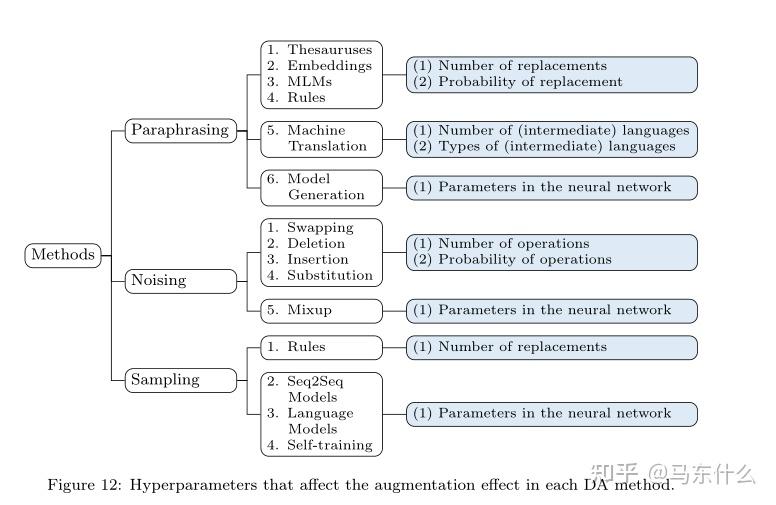
3.训练策略:
有些工作采用基于基本数据增强方法的训练策略。例如,Qu等[65]将回译与对抗性训练结合起来。类似地,Quteineh等人[34]将基本的预训练模型转化为一个优化问题,以最大化生成的输出的有用性。Hu等[94]和Liu等[95]使用预先训练过的语言模型来生成增强数据,并将此过程转化为强化学习。一些著作([61,596])采用了生成对抗网络的思想来生成具有挑战性的增强数据。
4. training objects
训练对象是模型训练的关键,特别是对于可学习的DA方法(例如mixup)。Nugent等人[64]提出了一个softmax的temperature的设置范围,以确保多样性,同时保留语义意义。Hou等人[67]利用重复意识注意和面向多样性的正则化生成更多样化的句子。Cheng等人[25]采用课程学习来鼓励模型关注困难的训练实例(喵喵喵???)。
5.过滤
在数据增强的过程中,有时不可避免地会引入一些噪声甚至误差,因此引入了过滤机制来避免这一问题。有些应用场景下,在初始阶段对部分输入数据进行过滤,以避免不适当的输入影响增强效果。一个典型的例子是句子长度,即过滤过短的句子([17])。Liu等人[27]在解决Math Word问题时过滤掉不相关的数字,而不增加它们,以确保生成的数据计算正确。此外,一些工作在最后阶段过滤合成的增强数据。这通常是通过模型实现的。例如,Zhang et al.[13]采用鉴别器对反向翻译结果进行过滤。Tavor et al.[30]和Peng et al.[21]都使用分类器对预训练模型生成的增广句子进行过滤,以保证数据质量。
1.nlp中的样本增强方法需要根据具体的场景有目标的进行增强,盲目的随便增强常常不work甚至反效果,对于粗粒度和细粒度,长中短文本或二分类,多分类,多标签等问题需要具体情况具体分析,例如在文本反欺诈的问题中,要根据欺诈用户的扰动方式来进行对应的文本增强,例如欺诈用户往地址中插入大量数字,则可以如法炮制进行随机的数字插入等;
2.样本增强是解决小样本问题和不均衡学习问题的最应该尝试的利器,样本少或者某类样本很少的情况下,其它的骚操作的潜在增益远远小于样本增强(其中包括浪费大量时间做各种各样乱七八糟的尝试,比如smoteboost和rusboost之流),可惜表格数据没有nlp这种数据形式具有的特性,很难做增强,否则,可能就没有imblearn什么事情了;
3.其它领域的增强不太清楚,但是文本领域的这些增强方法,个人认为最本质的能够work的原因在于,
(1) 从理论层面来说,更多的有效样本,使得经验风险最小化逐渐逼近期望风险最小化,这里需要提到的是样本必须是有效的,简单来说,我们通过增强得到的样本应该是在潜在的全量数据的分布中的,并且和训练样本的分布不能完全相同,可以更近一步的用训练集的分布来刻画潜在的全量数据的分布,如果只是简单的repeat样本达不到这样的效果,训练数据集整体的分布不会发生显著的有意义的趋向全量数据分布的变化,只是会让模型在训练的过程中相对于repeat之前更关注repeated 样本的区分情况;
2.从实际应用层面来说,让模型能够在训练的过程中提前的,直接或间接的看到未来会出现的样本信息,就类似于你打比赛提前已经猜到了测试集的标签然后放到你的训练数据里来,效果当然好的一笔啊,这主要是由于语言本身的特性导致的,因为语言在很长的一段时间里,其本质的规律不会发生大的变化,(这一点,和同样都是序列问题的时序应用的问题存在很大区别,时序的变化大的一笔),反过来想,假设某一天我们突然都用火星文而不用中文来交流了,或者我们都变成了结巴,以后说话每个字都要重复10次,那么目前大部分文本增强的方法就要die了.再换一个思路想,如果能够通过一些方法获取大量真实的数据,那岂不是更好哈哈哈哈哈,好像在说废话,比如花钱买,爬虫(你懂的,github上一大堆的项目)等等;
最后,在当前的业务层面上,重新审视一下上述的三种方法:
1.样本的扰动可能的原因来自于数据采集过程中的错误或者其它奇怪的原因,总之最后的结果就是样本不"干净"了,而模型在当前数据上又太过"完美"了,以至于未来的数据发生了变化之后效果变得很差,
那么我们通过增强的手段来提前将这类不"干净"的样本的信息直接或间接(adversial training例如FGM个人认为其实是一种隐式的样本生成的方法,从模型层面去进行间接的样本增强)提前在训练过程中引入这类样本.这是paraphase-based的方法和noise-based的方法在解决的问题,对抗非人为的数据扰动;
2.人为恶意的扰动,感觉这是task-specific类方法能够解决的问题,文本反欺诈中的欺诈手段很多时候很难通过一些广泛的通用的增强方法来生成和欺诈用户的欺诈文本相似的结果,因此需要引入特定于任务的,即特定于欺诈手段的方法来更好的进行增强.
1.预处理阶段增强:优点,简单方便,可以离线,和当前代码无缝衔接;
同/近义词替换:基于词典和静态词向量(word2vec,fasttext,glove之流)或动态的上下文向量(bert mlm pipiline('fill mask'),huggingface让这一切简单轻松)
加噪:随机替换,随机删除,
随机交换:升级版基于tfidf这类能够衡量token的重要程度的,替换不重要的token
回译:这玩意儿真的太强了,google traslate一个接口搞定,业务上precision提升了两个点以上。
针对不同语言还有很多特定于语言的增强方法:
中文的特点主要有:
1.拼音;三 san
2.字形(笔画);三 彡
3.谐音词: 三 丧
4.简体繁体: san 叁
5.中英混合: 三 three
6.中文数字:三 3
7.中文和特殊符号: 三 Ⅲ ③
。。。
具体的,需要针对不同场景下特定的问题使用不同的方法,粗粒度问题选择多,细粒度问题选择少。
待看paper:
EDA (Easy data augmentation) 看完了
LAMBADA
UDA:
Mixup:
万能半监督:看完了
对抗学习,对抗训练和对抗样本,survey:
文本生成survey:
以及:
JayJay:标注样本少怎么办?「文本增强+半监督学习」总结(从PseudoLabel到UDA/FixMatch)
jayjay大佬总结的一些方法.


版权声明
本文仅代表作者观点,不代表xx立场。
本文系作者授权xx发表,未经许可,不得转载。



评论列表
发表评论